一、简单介绍
1、什么是正則表達式
正則表達式本身就是一种语言,这在其他语言是通用的。
正則表達式(regular expression)描写叙述了一种字符串匹配的模式,能够用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
str.indexOf(‘abc’); //精确匹配 仅仅能匹配字符串“abc”
正則表達式 //模糊匹配
Where name=’zhangsan’; //精确匹配
Where name like ‘zhang%’; //姓名以zhang開始的字符串
2、为什么使用正則表達式
1)验证邮箱
2)手机号
3)银行卡号
4)採集器
186lO659839
5)中奖信息 186****9839
6)屏蔽特殊词汇
3、高速入门
1)查找一个字符串中是否具有数字“8”
2)查找一个字符串中是否具有数字
3)查找一个字符串中是否具有非数字
二、正则对象
要使用正則表達式,必须要在程序创建正则对象
1、怎样创建正则对象?
我们须要得到一个RegExp类的实例
1)隐式创建
var 对象=/匹配模式/匹配标志; ‘’ [] {}
2)直接实例化
var 对象=new RegExp(“匹配模式”,’匹配标志’);
以上两种使用方法差别:
Var reg=/d/gi;
假设使用直接实例化。那么像“d”这种字符。须要转义”d”。例如以下:
Var reg=new RegExp(“\d”,”gi”);
2、匹配标志:
g:全局匹配
i:忽略大写和小写
三、怎样使用正则对象
在js中,使用正则对象主要有两种使用方法:
1、RegExp类
test(str) :匹配指定的模式(參数)是否出如今字符串中(返回有没有)
reg.test(str);
exec(str) :返回匹配模式的字符串 (复杂,返回详细内容)
reg.exec(str);
2、Sring类
search :匹配符合匹配模式的字符串出现的位置。没有匹配到则返回-1
str.search(reg);
match :以数组形式返回匹配模式的字符串,没有匹配到则返回null
str.match(reg);
replace :使用指定的内容替换匹配模式的字符串
str.replace(reg,”content”);(两个參数)
split :使用匹配模式的字符串做为分隔符对字符串进行切割,返回数组
str.split(reg);
RegExp
- test
- exec
String
- Search
- Match
- Replace
- Split
不同的情况下使用不同的方法
如:
我想知道邮箱格式、手机格式、IP格式合不合法,用test
假设想抓取网页中全部的手机号。使用exec或match
想替换掉网页中敏感词汇,用replace
四、几个重要的概念
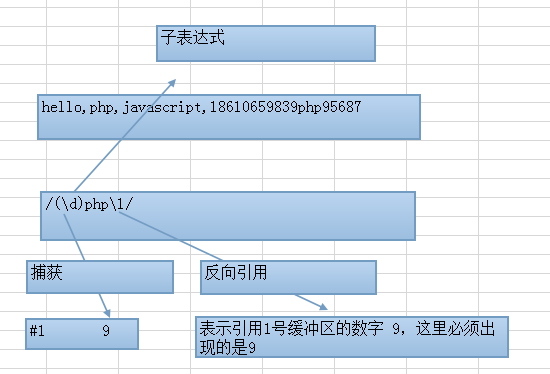
- 子表达式
在正则匹配模式中,使用一对括号括起来的内容是一个子表式
- 捕获
在正则匹配模式中,子表达式匹配到的内容会被系统捕获至系统的缓冲区中
- 反向引用(后向引用)
捕获之后,能够在匹配模式中,使用
(n:数字)来引用系统的第n号缓冲区内容
例1:
匹配多个字符后面是三个数字。后面的内容和前面多个字符同样,
如:abc123abc
例2:习题:
查找连续的四个数字。如:3569
var reg=/dddd/gi; d{4}
查找连续的同样的四个数字,如:1111
var reg=/(d)111/gi;
查找数字,如:1221,3443
Var reg=/(d)(d)21/gi;
查找字符,如:AABB,TTMM
Var reg=/(w)1(w)2/gi;
查找连续同样的四个数字或四个字符
Var reg=/(w)111/gi;
普通情况,后面的内容要求与前面的一致。就会用到子表达式、捕获、反向引用的概念
例3:在一个字符串,查找一对html标记以及中间的内容(好样例)
例4:关于子表达式和exec方法
exec方法和match方法的比較:
Exec方法是RegExp类下的方法
Match是String下的方法
Match方法直接返回一个数组
Exec方法须要使用循环重复调用
假设有子表达式,exec方法会将子表达式的捕获结果放到数组相应的数组元素中
五、正则语法细节
正則表達式是由普通字符(比如字符 a 到 z)以及特殊字符(称为元字符)组成的文字模式。正則表達式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
正則表達式的构成:
1)普通字符 :a b c d 1 2 3 4 ……..
2)特殊字符(元字符):d D w . …….
我们在写正則表達式的时候。须要确定这样几件事:
1)我们要查什么
2)我们要从哪查
3)我们要查多少
1、限定符
限定符能够指定正則表達式的一个给定组件必须要出现多少次才干满足匹配。
* — 匹配前面的组件零次或多次
+ — 匹配前面的组件一次或多次
?
— 匹配前面的组件零次或一次
{n} — 匹配确定的 n 次
{n,} — 至少匹配n 次
{n,m} — 最少匹配 n 次且最多匹配 m 次
也能够使用下面方式表示:
* == {0,}
+ =={1,}
?
=={0,1}
代码:
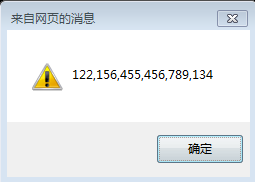
例1:

结果:
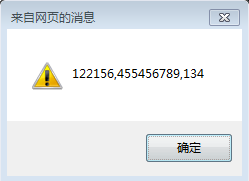
例2:

结果:
例3:

结果:
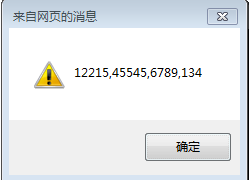
d{3,5} :如在上题字符串中,既匹配三个,也能够匹配五个,那么,正則表達式中会自己主动匹配多的那一种,这在正则中贪婪匹配原则。
假设在表达式的后面使用”?”,表示非贪婪匹配原则,就会尽可能匹配少的,示比例如以下:
例4:

{3,5}? 表示匹配3个
2、字符匹配符
字符匹配符用于匹配某个或某些字符
字符簇
- [a-z] :表示a-z随意一个字符
- [A-Z] :表示A-Z随意一个字符
- [0-9] :表示0-9随意一个数字
- [0-9a-z] :表示0-9 a-z随意一个字符
- [0-9a-zA-Z] :表示0-9 a-z A-Z随意一个字符
- [abcd] :表示a 或b 或c 或 d
- [1234] :表示 1 或2 或3 或 4
- [^a-z] :表示匹配除了a-z之间随意一个字符
- [^0-9] :表示匹配除了0-9之间随意一个字符
- [^abcd] :表示匹配除a b c d 之外的随意一个字符
- d :匹配一个数字字符。[0-9]
- D :匹配一个非数字字符。[^0-9]
- w :匹配包含下划线的不论什么单词字符。[0-9a-zA-Z_]
- W :匹配不论什么非单词字符。[^w]
- s :匹配不论什么空白字符 空格、制表符、换行符
- S :匹配不论什么非空白字符。
- . :匹配除 “ ” 之外的不论什么单个字符 假设想匹配随意字符 [. ]
3、定位符
定位符能够将一个正則表達式固定在一行的開始或结束。也能够创建仅仅在单词内或仅仅在单词的開始或结尾处出现的正則表達式。
^ 匹配输入字符串的開始位置
$ 匹配输入字符串的结束位置
b 匹配一个单词边界
B 匹配非单词边界
例1:
例2:验证年龄
4、转义符
用于匹配某些特殊字符
例1:
上题中。假设直接使用 /https://www.cnblogs.com/zhchoutai/p/ 匹配的是随意一个字符。我们仅仅想匹配字符‘.’,所以须要转义
须要的转义字符:
(
)
[
]
{
}
.
/
*
+
?
^
$
5、选择匹配符
| 能够匹配多个规则
代码:
六、关于正則表達式的几种特殊使用方法
1、(?
=)
正向预查
2、 (?!)
负向预查
3、 (?:)
匹配内容,结果不被捕获
上题中,(javascript|php)会被当做子表达式来处理,内容会被捕获。但在程序中,捕获的内容没有不论什么用途,这种情况下。能够使用(?
:)符合。让系统不去捕获子表达式匹配的内容
七、正则学习工具
代码:
八、正则习题:
1、验证手机号是否有效
2、验证邮箱是否有效
3、验证ip地址是否有效
九、结巴程序
结巴程序
我…我是是..一个个…帅帅帅帅…哥!”;
我是一个帅哥。
replace();
Try…catch语句
例1:
display()函数未定义,运行第5行代码时。出错,会被catch语句捕获,错误的相关信息会被保存到对象e中